I wanted to build a game with lots of AI NPC interactions. The issue was not just retrieval speed. The issue was bad context showing up at the wrong time.
You query memory, get a result, and the model basically says: this is bad context, I need better context. Then you run a wider search. That wider search is expensive and it also compounds latency when many NPCs are talking at once.
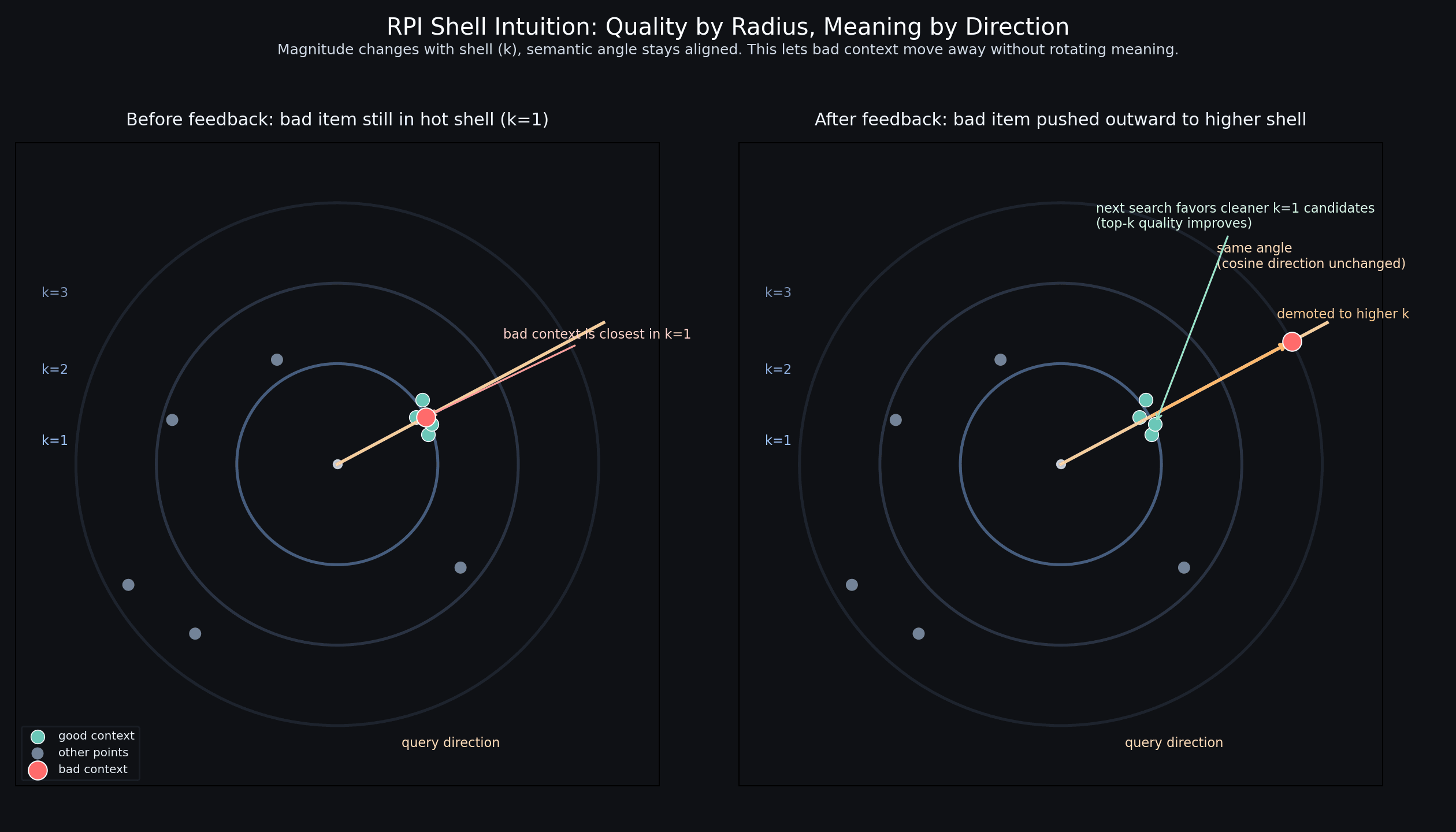
The thought was simple: if some memory keeps producing bad context, stop letting it stay in the hottest retrieval region. Move it farther away. Keep the trusted context near the center.
The idea in one paragraph
We forked Qdrant and implemented Radial Priority Indexing (RPI). Points live in shells: k=1 is high trust, k=2..N is lower trust. Good points get promoted inward over repeated wins. Bad points get demoted outward. Over time, k=1 becomes cleaner. Search starts at k=1 and only falls through if needed.
A key intuition is that changing only magnitude does not change cosine similarity directionally. The semantic direction stays stable. We then use Euclidean shell geometry for trust tiers and adaptive movement.
What we actually shipped
- Shell vectors per collection: rpi_shell_1 to rpi_shell_N.
- Collection-level RPI config at create time.
- Shell-aware search path with first-hit fallthrough.
- Promotion, demotion, eviction, and RPI runtime stats.
- gRPC parity for create and config readback.
- Strict lint, test, and release build gates passing.
Public-data benchmark run today
I wanted at least one benchmark that is not hand-picked toy data. So I ran a retrieval simulation today on the public 20 Newsgroups dataset. This is not a perfect production benchmark, but it is a legitimate, reproducible public corpus.
Setup: 5,000 train docs, 1,200 test docs, TF-IDF + SVD embeddings, baseline nearest retrieval vs RPI-style adaptive shell policy over 5 epochs.
| Metric | Baseline | RPI | Delta |
|---|---|---|---|
| Top-1 accuracy | 0.4550 | 0.6117 (epoch 5) | +34.44% relative |
| Wider-scope retry rate | 0.5400 (epoch 1) | 0.4167 (epoch 5) | -22.83% |
| Avg candidate set size | 5000 | 3989 | -20.22% |
Translation for game NPCs: with repeated interactions, we got better first answers and fewer expensive wider-scope retries.
Engine-level benchmark snapshots
From our Qdrant integration bench runs in this fork:
- Steady shell-1 latency stayed near baseline, usually low single-digit overhead.
- Cold or convergence phases were slower.
- Quality convergence in feedback loops was very strong.
Pros
- Self-correcting memory ranking over time.
- Better top-1 behavior in repeated-query, feedback-heavy workloads.
- Natural way to push noisy context away from the hot lane.
- Backwards-compatible default behavior for non-RPI collections.
Cons
- More moving parts than standard cache + ANN.
- Convergence phase can cost latency.
- Needs repeated interactions to show full upside.
- Not a free lunch for one-shot retrieval workloads.
Honest note
We vibecoded a lot of this fork, tests, and rewrites. No pretense that this is already a universal theorem for every stack. It is a practical idea that looks strong in the workloads we care about, and we are being explicit about where it can lose.
Also lmao, yes, this blog is AI-assisted with human intervention.
Where this is going
The goal is to use this memory policy inside dense NPC interaction loops where context quality matters more than raw nearest-neighbor purity. If your agent says context is bad, the system should learn and stop surfacing that context first.
That is the whole point of RPI for us: make k=1 progressively trustworthy without retraining the whole world every week.
Repro command used for the public-data run
python3 - <<'PY'
# 20 Newsgroups retrieval simulation using
# TF-IDF + SVD embeddings and RPI-style shell adaptation.
# (Script executed during this writeup.)
PY